Halb-Automatische Annotation funktioneller, semantischer und pragmatischer Rollen für ob-ugrische Texte
Ausgehend von bestimmten, wiederkehrenden Regularitäten der Syntax / Morphosyntax ob-ugrischer Sprachen können bestimmte Strukturen in Form formaler Regeln erfasst und darauf basierend Sätze mittels Parsing analysiert, den syntaktischen Einheiten syntaktische und semantische Funktionen zugewiesen und grundlegende informationsstrukturelle Muster annotiert werden. Auch das Reference-Tracking, d.h. das Verfolgen eines bestimmten Referenten im Textverlauf ist Bestandteil der Annotation. Basis des Parsings bilden die Angaben zur Wortart (und teilweise Informationen weiterer Analyseebenen), welche Bestandteil der Glossierung und Bearbeitung der Texte mittels FLEx (Field Language Explorer) waren. Mit diesen als Terminalsymbolen wurden die Sätze des jeweiligen Textes syntaktisch analysiert und die Ergebnisse verwendet für ein heuristisches Tagging der festgestellten syntaktischen Einheiten; dessen Ergebnis wurde wiederum in einem Formular mit entsprechenden Feldern zusätzlich zur Glossierung dargestellt. Ebenfalls können in dieser Ansicht die automatisierten Ergebnisse kontrolliert, bearbeitet und vervollständigt werden (semi-automatische Annotation).
Kurze Beschreibung Outline und Ablauf der Annotation
Schritt 1: Zuweisen von Phrasen / Parsing
Mithilfe der Information zur Bestimmung der Wortarten in FLEx werden zuvor festgelegte Kombinationen zu Phrasen geparst, z.B. die Abfolge Demonstrativpronomen Substantiv zu Nominalphrase (NP), Adjektiv Substantiv zu NP oder Präfix und Verb zur finiten Verbalphrase (finVP). Der Parser erfasst dabei eine Einheit nach der nächsten und gruppiert eine Phrase, sobald sie einer als Befehl im Skript eingetragenen Kombination entspricht. Auf diese Weise können auch feinere Unterschiede getroffen werden (z.B. NP und postpositionaler Phrase (PostP)). Besteht eine Zeile der Glossierung aus mehreren Sätzen (d.h. mehreren Prädikaten), so können diese mit eckigen Klammern voneinander getrennt werden. Die Bestandteile der einzelnen Sätze erscheinen dann jeweils in einer eigenen Farbe.
Zur besseren Orientierung und Zuordnung der einzelnen Satzglieder wird die fortlaufende Nummerierung mit in der Glossierung angezeigt. Zusammengehörende Satzglieder sind mit eckigen Klammern gekennzeichnet, die zugehörigen Felder stehen unter dem Bestandteil, das den rechten Rand der Phrase bildet, d.h. head-final.
 Abbildung 1: Zuordnung in mehrere Sätze (farbig) im Parsing; NM (ID 745, Nr. 2)
Abbildung 1: Zuordnung in mehrere Sätze (farbig) im Parsing; NM (ID 745, Nr. 2)
Zusätzlich zur Visualisierung unter der Glossierung wird im Feld phrasal annotation der Parsebaum eines Satzes schematisch dargestellt (s.u.). In diesem Feld kann gegebenenfalls das Ergebnis erweitert oder korrigiert werden. (Das ursprüngliche Parsingergebnis wird in einer weiteren Zeile als Vergleichswert angezeigt, Änderungen werden hier über eine diff-Funktion farbig angezeigt).
Im 'Reset Annotation' Mode (Auswahl über einen Knopf am Beginn der Seite) wird bei Änderung des Parsebaums das automatische Tagging auf Grundlage dieser Daten neu durchgeführt, im Standardmodus bleiben die alten Angaben erhalten.
 Abbildung 2: Feld Phrasal Annotation mit Bearbeitungsmöglichkeit (oben) und Ergebnis automatisches Parsing zum Vergleich (unten, inaktiv); NM (ID 745, Nr. 2)
Abbildung 2: Feld Phrasal Annotation mit Bearbeitungsmöglichkeit (oben) und Ergebnis automatisches Parsing zum Vergleich (unten, inaktiv); NM (ID 745, Nr. 2)
Schritt 2: Annotation syntaktischer, semantischer und pragmatischer Rollen
Nach dem Abspeichern der Parsing-Ergebnisse werden die Informationen der phrasal annotation in vier Zeilen unter dem glossierten Text angezeigt.
Die vier Zeilen enthalten die funktionalen (syntaktischen), semantischen und pragmatischen Tags sowie die numerische Zuweisung der einzelnen Referenten eines Textes.
 Abbildung 3: Funktionale, semantische und pragmatische Annotation und Nummerierung der Referenten; NM (ID 745, Nr. 2)
Abbildung 3: Funktionale, semantische und pragmatische Annotation und Nummerierung der Referenten; NM (ID 745, Nr. 2)
Der Großteil der Tags kann automatisch zugewiesen werden, muss aber kontrolliert und ggf. nachkorrigiert werden. Dazu erscheint eine Liste der Standard-Tags als Auswahl, sobald man das jeweilige Feld anklickt. Referenten müssen von Hand nummeriert werden, nach dem Abspeichern (
save functional annotations), werden die Referenten jedoch ebenfalls als Standard-Tags gespeichert und stehen danach in der Auswahlliste ebenfalls zur Verfügung.
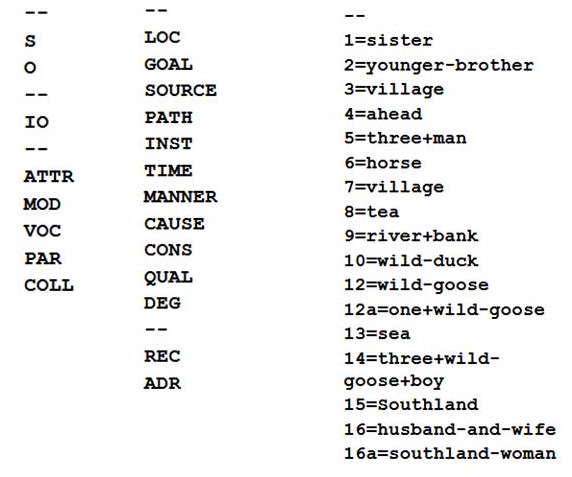 Abbildung 4: Auswahllisten für funktionale Tags (links), semantische Tags (mitte) und Referenten (rechts)
Abbildung 4: Auswahllisten für funktionale Tags (links), semantische Tags (mitte) und Referenten (rechts)
Eine weitere Möglichkeit bietet der 'Speech Annotation' Mode: dieser funktioniert analog zu den beiden anderen Modi und ist ebenfalls über einen Knopf am Beginn der Seite auswählbar. In diesem Modus erscheint über jedem Satz ein Hinweis, ob es sich hier um direkte Rede handelt. Die Informationen können ebenfalls automatisiert ausgelesen werden (über die jeweilige Information zur Person in der Glossierung) und bei Bedarf manuell korrigiert werden. Die detaillierte Anleitung zur Annotation findet sich hier.
Theoretischer Hintergrund
Das Parsing wurde eigens für die Ob-Ugrischen Sprachen entwickelt. Grundlage bildet die informationsstrukturelle Gliederung des Satzes in den ob-ugrischen Sprachen. Hierdurch wird u.a. die Satzstellung bestimmt, die Zuordnung syntaktischer Rollen zu den jeweiligen Referenten sowie deren Repräsentation im Satz. So wird die Rolle des primären Topik (auch Diskurs-Topik) vorwiegend als Subjekt realisiert, welches an satzinitialer Position steht und vorwiegend als Leerstelle (Nullanapher) im Satz realisiert wird. Diese Leerstelle erscheint somit in nahezu jedem Satz, kann jedoch, da sie somit keine Information zum Parsing zur Verfügung stellt, nicht automatisch erkannt werden. Zieht man jedoch andere Regularitäten heran, kann ein Großteil der Leerstellen (d.h. Subjekte und auch direkte Objekte) automatisiert beim Parsing mit eingefügt werden kann. So können z.B. in Sätzen, die nur aus einer VP bestehen, automatisch eine Leerstelle vor der VP und in Sätzen, die nur aus einer VP mit objektiver Konjugation bestehen, zwei zugewiesen werden.

Abbildung 5: Visualisierung der Leerstellen in der Annotation; NM (ID 1229, Nr. 6)
Mit Berücksichtigung der Wortfolge (SOV) kann die erste Leerstelle automatisch als Subjekt und die zweite als direktes Objekt annotiert werden.

Abbildung 6: Leerstellen mit funktionalen Tags; NM (ID 1229, Nr. 6)
Eine detaillierte Beschreibung zum theoretischen Hintergrund, auf dem die Annotation basiert, kann hier eingesehen werden.
Technische Umsetzung
Technisch wurde die Annotation syntaktischer Einheiten durch die Erweiterung der Ansicht der glossierten Korpusdaten um ein Eingabeformular für die Annotatoren umgesetzt, das sowohl eine Kontrolle und ggf. Nachkorrektur der Ergebnisse des automatischen Parsings als auch ein Überprüfen bzw. Vervollständigen des Taggins dieser Einheiten erlaubt.
Phrasale Einheiten werden basierend auf den part-of-speech-Tags des glossierten Korpus satzweise durch einen in die PHP-Plattform integrierten Parsing-Algorithmus bestimmt, der auf einer einfachen, im Laufe der Projekts entwickelten und verfeinerten Phrasenstrukturgrammatik mit nicht-rekursiven Regeln arbeitet (einige grammatikalische Merkmale werden ebenso berücksichtigt) und anschließend ergänzt wird durch Heuristiken für die Erkennung einfacher Sätze (clauses) sowie für das Einfügen von analytischen zero- und px-Elementen. Dieses Parsingergebnis wird anschließend in die Datenbank geschrieben und wird dem Annotator in seiner Annotationsansicht angezeigt; nach Bestätigung oder ggf. Korrektur wird das Ergebnis in einer weiteren Tabelle in der Datenbank abgespeichert, die hier identifizierten clause- und Phraseneinheiten werden in ein PHP-Array transformiert und der Tagging-Heuristik übergeben (s. oben). Das Ergebnis dieses automatische Taggings der syntaktischen Einheiten wird in eine entsprechende Tabelle in der Datenbank geschrieben (Einheiten sind über die Text- sowie die Tokennummer mit den Tokens des Korpus verknüpft, zusätzlich sind analytische Einheiten enthalten), und sofort (per AJAX, also asynchron) auf der Website angezeigt. In den nun vorhandenen Feldern können die Ergebnisse des Taggings noch nachkorrigiert werden sowie das Referenten-Tagging durchgeführt werden, das zwar manuell geschieht, aber durch die Auswahl aus den bereits vorhandenen Referenten unterstützt wird (auch asychron, also bei Tagging eines neuen Referenten sofort in den folgendenen Sätzen verfügbar).
Die wichtigsten Tags in der Annotation
Die meisten verwendeten Tags entsprechen den gängigen Abkürzungen syntaktischer, semantischer und pragmatischer Rollen und sind weitestgehend selbst erklärend. Die häufigsten Phrasen Tags sind z.B.:
| Tag |
Name |
| NP |
Nominalphrase |
| PronP |
Pronominalphrase |
| zero |
Nullanapher |
| locNP |
Nominalphrase im Lokalkasus |
| postP |
Postpositionale Phrase |
| VP |
Verbalphrase |
Es wurden einige Besonderheiten, welche auch für das Zuweisen weiterer Tags auf den anderen Ebenen nötig waren, berücksichtigt. So werden verschiedene Tags für Verbalphrasen (VP) verwendet, u.a. bei der objektiven Konjugation (okVP; benötigt für die Zuweisung von zwei Zeros) oder beim Passiv (passVP; benötigt, um dem Subjekt die semantischen Rolle Patiens zuzuweisen).
Die funktionalen Tags sind ebenfalls transparent gehalten und orientieren sich z.B. an Dik 1997:
| Tag |
Name |
| S |
Subjekt des Satzes |
| O |
direktes Objekt des Satzes |
| IO |
indirektes Objekt des Satzes |
| PRED |
Prädikat des Satzes |
Die Auswahl der semantischen Tags wurde recht übersichtlich gehalten, um einerseits die automatische Annotation und andererseits Einheitlichkeit bei der Nachkorrektur bei verschiedenen Bearbeitern zu gewährleisten. So wird beispielsweise auf die Unterscheidung von Patiens und Thema verzichtet, da der Aufwand, die Daten für die automatische Annotation anzupassen, nicht im Verhältnis der erreichbaren automatisierten Zuweisung steht. Stattdessen haben sich die Vorarbeiten zur automatisierten Annotation auf solche Bereiche konzentriert, welche in Hinblick auf die Typologie der ob-ugrischen Sprachen hilfreiche Erkenntnisse liefern, so z.B. die lokaladverbialen Bestimmungen. Auch die Belebtheit des Referenten wurde berücksichtigt.
| Tag |
Name |
| AG |
Agens |
PAT |
Patiens |
| REC |
Recipient |
| COM |
Komitativ (blebt) |
| LOC |
Lokativ |
| GOAL |
Ziel |
| SOURCE |
Quelle |
| PATH |
Pfad |
| INST |
Instrument (unbelebt) |
Die automatisierte Annotation der pragmatischen Rollen birgt die größten Herausforderungen und kann nur bis zu einem gewissen Grad erfolgen. Sie wurde daher so vereinfacht wie möglich konzipiert, ohne dabei ihre Berechtigung, überhaupt annotiert zu werden, zu verlieren. Für die automatische Zuweisung wurden ebenfalls bestimmte Eigenschaften des Satzes herangezogen, welche auf der informationsstrukturellen Gliederung des Ob-Ugrischen beruhen. Da beispielsweise die Topikalität eines Referenten weniger „Kodierungsmaterial“ bei der Wahl des referentiellen Verweismittels erfordert (bis hin zur Nullanapher für sehr höchst saliente Referenten), wurde im Umkehrschluss daraus die automatische Annotation aller Leerstellen (Zeros) mit dem Tag TOP. Das Prädikat des Satzes wird standardmäßig als Fokus annotiert. Die automatische Annotation garantiert somit eine grobe schematische Darstellung der pragmatischen Analyseebene. Ergänzend dazu ist es möglich - gewisse Kenntnisse der Informationsstruktur im ob-ugrischen Satz vorausgesetzt - diese automatisierten Tags manuell nachzubearbeiten. Dazu stehen weitere Tags in der Auswahl zur Verfügung.
| Tag |
Name |
Beschreibung |
| TOP |
Topik |
Satzteil, der das Topik des Satzes (hier den topikalen Referenten) kodiert. |
| FRAME |
„Frame-Settting“ |
Für gewöhnlich ein einleitender Satz zu Beginn einer Erzählung oder einem Abschnitt mit neuer Handlung; meist Informationen zu Zeit, Ort, beteiligten Personen.
Das Frame-Setting muss nicht zwangsläufig im ersten Satz erfolgen, ist jedoch dort typisch. Beginnt ein Text stattdessen gleich mit dem tatsächlichen Handlungsverlauf, kann auch mit FOC getaggt werden. Umgekehrt kann auch zu Beginn eines neuen Abschnitts ein Frame-Setting erfolgen. |
| FOC |
Fokus |
Satzteil, das den Fokus (hier die neue Information) beinhaltet. |
Den im Handlungsverlauf involvierten Referenten wird in der Reihenfolge, in der sie zum ersten Mal auftreten, manuell eine fortlaufende Nummer zugewiesen. Hat ein Referent seine Nummerierung erhalten, erscheinen Nummer und die erste Referenz im Text (im Normalfall eine Nominalphrase) fortan in der Auswahlliste. Gelegentlich erfolgen Handlungen von mehreren Referenten zusammen, was ebenfalls mit bestimmten Tags festgehalten werden kann.
| Tag |
Beschreibung |
| 1 |
Referent 1 |
| 1+2 |
Referent 1 und 2; Dual |
| 1+2+3 |
Referent 1, 2 und 3; Plural |
| 2a |
Das Tag Referent 2 bezieht sich auf eine Gruppe, Referent 2a ist ein in der Gruppe vorerwähnter, jetzt alleine an der Handlung beteiligter Referent. |
Die Annotation erfolgt linear, d.h. der Satz wird analog zu seiner Darstellung in der Glossierung auf einer Ebene annotiert. Dies wurde ebenfalls bei der Annotation von z.B. subordinierten Partizipialkonstruktionen berücksichtigt. Die Beschreibung hierzu sowie einiger weiterer Besonderheiten bei der Annotation (z.B. von Possessivkonstruktionen) sind, zusammen mit den vollständigen Listen der funktionalen, semantischen und pragmatischen Tags,
hier nachzulesen.
Ergebnis und Weiterverwendung
Mithilfe der Annotation kann das Zusammenspiel von grammatischer und pragmatischer Information und deren Auswirkung auf die Struktur des ob-ugrischen Satzes verdeutlicht und text-basiert beschrieben werden. Dazu ist nicht nur die Darstellung des annotierten Texts an sich hilfreich, sondern auch eine Analyse der Ergebnisse der Annotation. Mithilfe der funktionalen und semantischen Tags können beispielsweise die Verwendung von Kasus (zum Ausdruck syntaktischer oder adverbialer Bestimmungen) korpus-basiert ausgewertet werden und eventuell sogar detaillierte Aussagen zur jeweiligen Funktion beim Zusammenfall bestimmter Kasus (z.B. dem Dativ-Lativ) getroffen werden. Mithilfe der pragmatischen und referentiellen Tags können beispielsweise Anzahl, Häufigkeit des Auftretens und die Wahl des referentiellen Verweismittels der im Text vorkommenden Referenten dargestellt werden. Damit können detailliertere Aussagen zur Topikalität einzelner Referenten gemacht werden. Ebenfalls ist es möglich, das Reference-Tracking, das Verfolgen eines bestimmten Referenten im Textverlauf mithilfe Daten der Annotation auszuwerten und zu visualisieren.
Der gesamte annotierte Text kann exportiert werden, z.B. als Quelle im Anhang bei Textanalysen. Alternativ können einzelne Sätze exportiert werden und direkt als Beispiele im Fließtext (z.B. mit LaTeX) integriert werden.
Zum annotierten Textkorpus gelangen Sie hier.

